Libraries tagged by data integration
xefi/faker-php-symfony
97 Downloads
Faker PHP integration with Symfony
digital-marketing-framework/drupal-distributor-core
145 Downloads
Anyrel distributor integration for Drupal
blocktrail/blocktrail-sdk
21117 Downloads
The BlockTrail PHP SDK, for integration of Bitcoin functionality through the BlockTrail API
atk4/filestore
26026 Downloads
Integration between ATK UI Form Upload Field and PHP Flysystem
asciisd/autochartist-laravel
85 Downloads
Autochartist API integration with Laravel
akeneo/custom-entity-bundle
2724 Downloads
Akeneo PIM Custom entity bundle
swissup/module-breeze-mageants-estimateddeliverydate
623 Downloads
Mageants Estimated Delivery Date integration with Breeze Frontend
calliostro/last-fm-client-bundle
391 Downloads
Ultra-lightweight Symfony bundle for the Last.fm API — music scrobbling, data & integration made easy
calliostro/discogs-bundle
764 Downloads
Ultra-lightweight Symfony bundle for the Discogs API — vinyl, music data & integration made easy
romanzipp/laravel-dto
5423 Downloads
A strongly typed Data Transfer Object integration for Laravel
weprovide/magento2-module-headroom
19694 Downloads
data-mage-init integration for Headroom.js
mageworx/module-deliverydate-stock-validation
686 Downloads
Delivery Date and Magento MSI integration
doyosi/whois
247 Downloads
WHOIS lookup library for PHP - Query 70+ WHOIS servers directly, parse responses for 20+ TLDs, build raw WHOIS APIs, domain availability checkers, and registration info tools. Features plugin system for custom parsers, Laravel integration, IDN support, and 30+ date format handling.
briqpay/php-sdk
11949 Downloads
This is the API documentation for Briqpay. You can find out more about us and our offering at our website [https://briqpay.com](https://briqpay.com) In order to get credentials to the playgrund API Please register at [https://app.briqpay.com](https://app.briqpay.com) # Introduction Briqpay Checkout is an inline checkout solution for your b2b ecommerce. Briqpay Checkout gives you the flexibility of controlling your payment methods and credit rules while optimizing the UX for your customers # SDKs Briqpay offers standard SDKs to PHP and .NET based on these swagger definitions. You can download them respively or use our swagger defintitions to codegen your own versions. #### For .NET `` Install-Package Briqpay `` #### For PHP `` composer require briqpay/php-sdk `` # Standard use-case As a first step of integration you will need to create a checkout session. \n\nIn this session you provide Briqpay with the basic information necessary. In the response from briqpay you will recieve a htmlsnippet that is to be inserted into your frontend. The snippet provided by briqpay will render an iframe where the user will complete the purchase. Once completed, briqpay will redirect the customer to a confirmation page that you have defined. 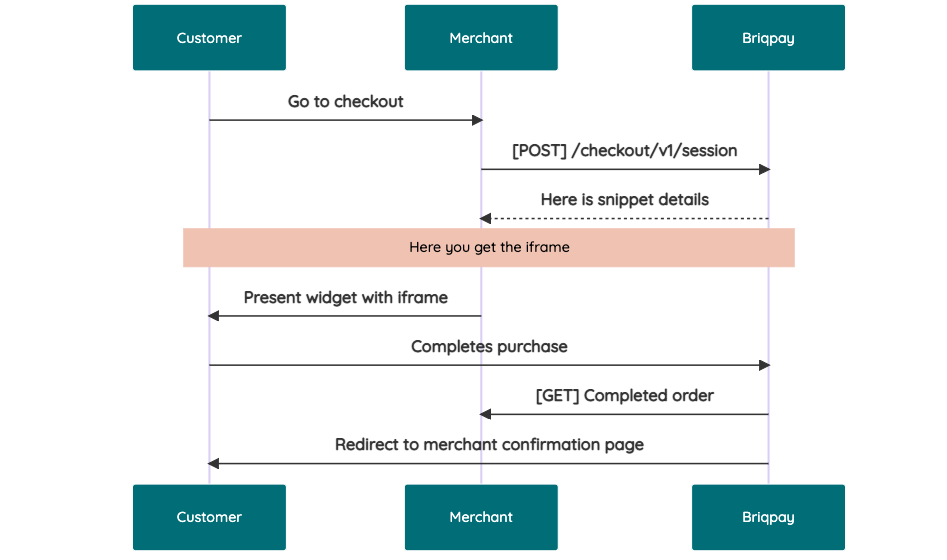 # JavaScript SDK The first step of integration is to add our JS to your site just before closing the ```` tag. This ensures that our JS library is avaliable to load the checkout. ```` Briqpay offers a few methods avaliable through our Javascript SDK. The library is added by our iframe and is avalable on ``window._briqpay`` If you offer the posibility to update the cart or order amonts on the checkout page, the JS library will help you. If your store charges the customer different costs and fees depening on their shipping location, you can listen to the ``addressupdate``event in order to re-calculate the total cost. ```javascript window._briqpay.subscribe('addressupdate', function (data) { console.log(data) }) ``` If your frontend needs to perform an action whe the signup has completed, listen to the ``signup_finalized`` event. ```javascript window._briqpay.subscribe('signup_finalized', function (status) { // redirect or handle status 'success' / 'failure' }) ``` If you allow customers to change the total cart value, you can utilise the JS library to suspend the iframe while you perform a backen update call towards our services. As described below: 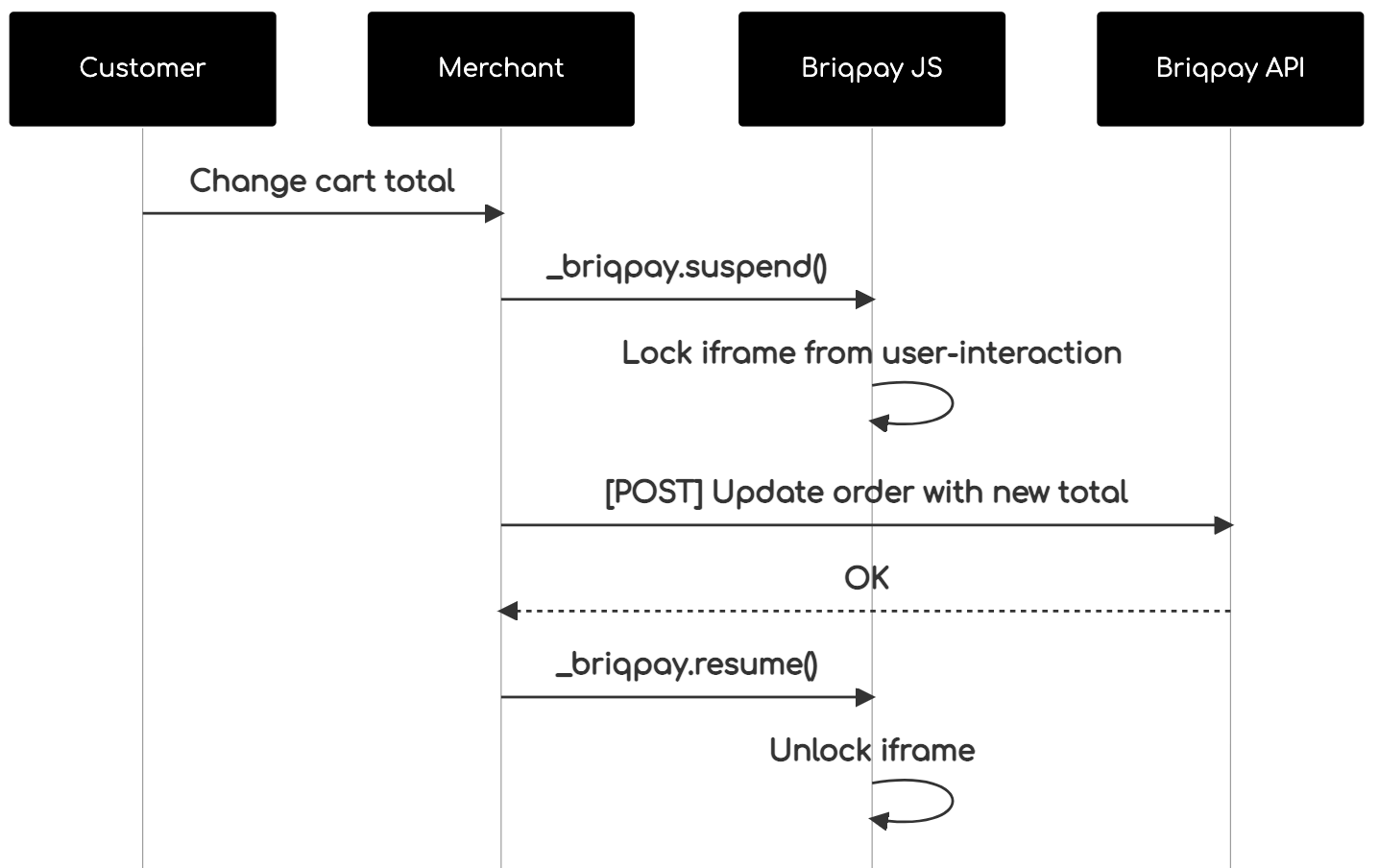 The iframe will auto-resume after 7 seconds if you dont call ``_briqpay.resume()`` before # Test Data In order to verify your integration you will neeed to use test data towards our credit engine. ## Company identication numbers * 1111111111 - To recieve a high credit scoring company ( 100 in rating) * 2222222222 - To test the enviournment with a bad credit scoring company (10 in rating) ## Card details In our playground setup your account is by default setup with a Stripe integration. In order to test out the card form you can use the below card numbers: * 4000002500003155 - To mock 3ds authentication window * 4000000000000069 Charge is declined with an expired_card code. You can use any valid expiry and CVC code # Authentication Briqpay utilizes JWT in order to authenticate calls to our platform. Authentication tokens expire after 48 hours, and at that point you can generate a new token for the given resource using the ``/auth`` endpoint. - Basic Auth - only used on the auth endpoint in order to get the Bearer Token - JWT Bearer Token - All calls towards the API utlizes this method"
raiolanetworks/plugin-seo-test
1630 Downloads
This Composer package provides a seamless integration for testing SEO aspects of your Laravel applications. Compatible with both Pest and PHPUnit, it offers a collection of tools and assertions specifically designed to evaluate on-page SEO elements like meta tags, title tags, canonical URLs, and structured data. By automating SEO testing, this plugin ensures that your application consistently adheres to best SEO practices, helping you catch potential SEO issues early in the development cycle.